3 Things I Learned When Trying to Predict the Masters with Machine Learning
As an avid golf fan, I set out to predict the 2020 Masters using my analytics and coding knowledge. I discovered (and confirmed) many exciting details about golf, data science, and human nature throughout the process.
- The old adage — “Drive for show, putt for dough,” does not always apply to the Masters, believe it or not.
- You could design and build an extremely accurate model based on training data, but it won’t work if your data does not reflect reality.
- One can’t forget about a significant and specific aspect of athletic performance…who has the hot hand!
The Masters is not only the most prestigious and celebrated tournament in golf, but it is also the only Major that is played at the same course year after year. Thus, it is a data scientist’s dream because one of the essential factors in determining a golfer’s success remains constant, the course. This constant makes it much easier to predict who will do well based on their historical stats.
The following analysis is built upon the idea that golfers with certain skillsets perform better at certain courses. For example, at the 2017 US Open at Erin Hills, we saw big hitters have a lot of success because it was a long and open course. Therefore, since the Masters takes place at Augusta National every year, it should be plausible to accurately predict player success based on statistics.
Augusta National is famous for its challenging greens, so the traditional assumption is that you need to be a fantastic putter to succeed at the Masters. While it is always nice to be a great putter, we’ll see what other player characteristics can lead to winning a green jacket.
Below, I will describe how I built a classification machine learning model with one goal in mind — predict the winner of the 2020 Masters.
Spoiler: I did not pick DJ, but I’ll get into why not.
Gathering Data
As previously mentioned, this analysis’s fundamental idea is that certain players perform better at specific courses because the best parts of their game translate well to that course. Therefore, I needed to get data that describes each player’s iron play, driving, putting, chipping, etc.
I used a web scraper to gather data from 2005 to 2020 for every Masters participant and the following stats from that season:
- wins
- top 10s
- score average
- bounce back %
- driving accuracy %
- driving distance
- greens in regulation %
- putts per round
- scramble %
- strokes gained putting
- strokes gained tee-to-green
- strokes gained total
- strokes gained approach
- strokes gained off the tee
- strokes gained around the green
- par 3 scoring average
- par 4 scoring average
- par 5 scoring average
- proximity to the hole
Each row in the dataset is a player, his stats, and Masters finish for that year. For example, 2005 Tiger Woods and 2006 Tiger Woods are treated as two different data points. The idea behind this is that a one year sample is a good way to determine a player’s skill in different categories that year. Since I used a full season’s worth of data, it includes the stats that the player had that season after the Masters since the tournament is typically towards the middle of the season. However, this was only the case for the training data. I did this because I solely focused on player characteristics rather than how they were playing leading up to the tournament (this ended up being my biggest mistake, but more on that later). And, since the Masters was postponed till November because of COVID-19, I would use a player’s entire 2020 season stats to make the predictions for this year’s tournament.
Below is a snapshot of the dataset:

Note: There is no Aaron Baddeley data for 2010 because he did not play in the Masters that year.
Next, it was time to do some exploratory analysis before building the model.
Exploratory Analysis
Note: The code I created for the following analysis, and to build the model can be found at this link: https://github.com/samegreene55/masters-machine-learning
The first step was to look at a histogram of each variable to ensure no extreme skew that could affect the model.
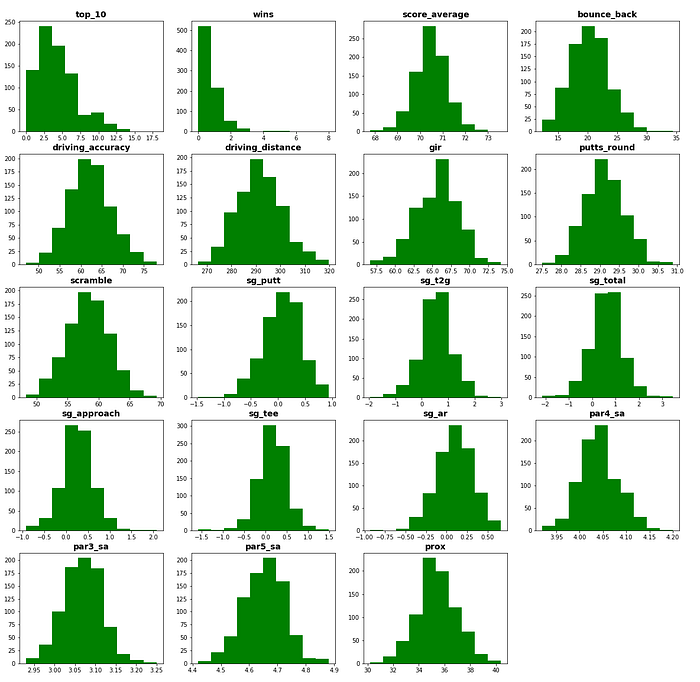
We can see that every variable is close to normally distributed except for top 10s and wins, which are very skewed right. Next, I wanted to visualize how Masters winners performed in a season compared to everyone else for each stat. In the following figure, the left box plots represent the winners, while the right box plots represent everyone else.
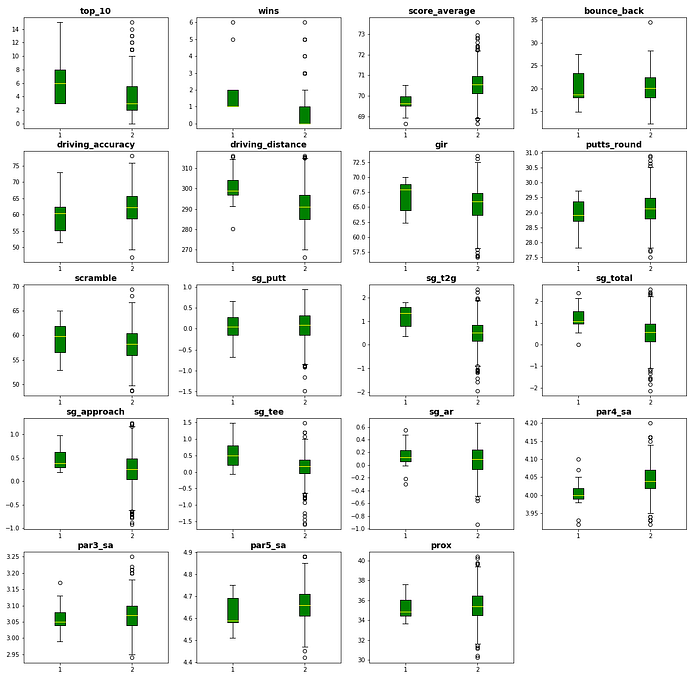
What jumps out right away is that Masters winners hit the ball further than their competition (driving distance), hit more greens (gir), are clearly better in terms of total strokes gained (sg_total), strokes gained tee to green (sg_t2g), strokes gained off the tee (sg_tee), and perform better on par 4s (par4_sa). Also, to no surprise, the winners have a significantly lower score average throughout each season.
What is surprising, however, is that over the past 15 years, Masters winners have been rather average putters, as shown by the strokes gained putting (sg_putt) and putts per round (putts_round) boxplots. Also, they seem to be less accurate off the tee (driving_accuracy).
I removed top 10s and wins from the analysis after this step because of their extreme skew and because they don’t describe a player’s skill in a particular aspect of the game.
Next, it was time to pick an algorithm to build and train a model with the data to predict the 2020 winner.
Model Building
I decided to build a classification model that would split the data into two groups… winners, and everyone else. Thus, I built and tested a Random Forest Classifier and a Support Vector Classifier. Without getting too into the math, a Random Forest uses decision trees that iteratively split the data into different groups based on each predictor, eventually forming the final classification nodes. On the other hand, a Support Vector machine divides the data into groups based on the optimal hyperplanes. Therefore, these two algorithms would be ideal for splitting players into winners and non-winners. I would go on to test both models and pick the best one to use for this task.
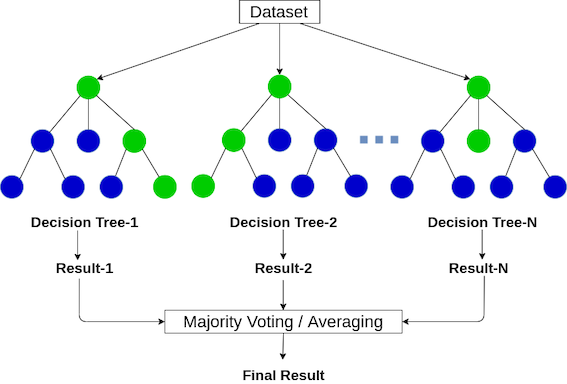

Because there are roughly 100 tournament entrants every year and only 1 winner, the data is extremely unbalanced. To solve this issue, I used the Synthetic Minority Oversampling Technique (SMOTE) to create synthetic winners every year. This technique works by taking a random sample from the minority class (the winner) and choosing a certain number of the nearest neighbors to that data point (I went with 3). It then randomly picks one of those neighbors and creates a synthetic winner at a randomly selected point between those two samples in the feature space. Then, to further balance the data, I also under-sampled the majority class (non-winners). I wanted the model to give me a few predicted winners. After testing the models with different ratios, the best performing one oversampled the winners to have 10 winners for each year and only took 50 non-winners to have a 1–5 ratio.
I then tested these two models using a technical Leave One Out Cross-Validation test (LOOCV). I ran the models 13 times, each time leaving out one year as the test data. So I trained the models on 12 years of data and tested it on the left out year.
Note: I only used 13 of the 15 years that I had data for, as I removed Tiger Woods’ win last year since he played very few tournaments outside of the Masters. Also, the PGA tour site did not allow for scraping of driving distance for 2016, so that year was taken out as well.
To compare the two models’ performance, I recorded the precision, recall, and accuracy score. Precision is the probability that a predicted winner actually wins. Recall being the probability that the winner was in the set of predicted winners, and Accuracy is the probability that each prediction is correct. So, in this case, we want to focus on high recall because the model will predict a set of winners, and if the actual winner is always in that set, this model can prove to be useful for betting on the tournament. However, we don’t want the precision to be too low because theoretically, the model could predict half the field as winners and have a very high recall, and there is no benefit in that.
Below are the results from the technical LOOCV Test:

We can see that the linear SVM model had the best recall by far while not sacrificing too much precision. It also predicted, on average, over 6 winners. This seems like a lot. However, if over 50% of the time, the actual winner is in that set of predicted winners, and a golf bettor bets on each of those predicted winners to win the tournament, they stand to get a substantial payout. Especially since even the favorites for the Masters have odds below 8 to 1 (Bryson DeChambeau this year was 17–2). Therefore, I decided to use the linear SVM model to get my set of predicted winners for this upcoming year.
Results
The model picked the following five golfers, and here’s how they finished:
- Justin Thomas (-12, 4th)
- Rory McIlroy (-11, T5th)
- Patrick Reed (-9, T10th)
- Scottie Scheffler (-6, T19th)
- Tony Finau (-1, T38th)
What is interesting to note is that Thomas, McIlroy, Scheffler, and Finau all share very similar characteristics. They are long off the tee, above-average iron players, and mediocre to below-average putters. Meanwhile, Reed is the opposite. He is an above-average putter and not a great ball striker. This tells me that a lot of the time, the Masters winner resembles players like Thomas, McIlroy, Scheffler, and Finau, while sometimes being a great putter can save you at Augusta.
Unfortunately, Dustin Johnson played his best golf, and although for a while it looked like JT and Patrick Reed had a shot, they came up short. If Rory didn’t struggle so much in round 1, he could have given DJ more of a scare. Although all five predicted winners made the cut, three finished in the top 10, and two finished in the top 5. So clearly, there is some merit to this analysis.
But after a long weekend of being glued to the TV, watching DJ tear up Augusta National and make me question my future in sports analytics, I was left wondering…how in the world did the model not pick Dustin Johnson?
Why the Model Didn’t Pick Dustin Johnson
(AKA How I Messed UP)
The odd timing of the Masters this year prompted me to do this analysis because I figured I had a whole season’s worth of data to use as prediction data. When I was scraping the PGA site, I assumed the Masters was still a part of the 2020 season, so I only gathered data for the 2020 season. Going back, I realized that the 2020 season ended with the Tour Championship (duh) in early September. Since then, nine tournaments have taken place and were not included in the players’ stats to make the predictions because they were part of the 2021 PGA Tour season.
I then gathered the data for the 2021 season (those nine tournaments) and ran the exact same SVM model, and guess who it picked…Dustin Johnson. In fact, it chose the following players:
- Dustin Johnson (-20, 1st)
- Justin Thomas (-12, 4th)
- Brooks Koepka (-10, T7th)
- Hideki Matsuyama (-8, T13th)
- Tyrell Hatton (+3, CUT)
To put my money where my mouth is, I had bet $20 on each of the originally predicted winners to win, so had I not made this mistake, I would be at least $100 richer… but you live, and you learn.
This mistake taught me that I need to pay more attention when gathering data and that play leading up to the tournament can be very crucial in predicting the winner. Even though Johnson did not have the best 2020 season in terms of stats, he was on fire heading into the Masters this year, as shown by his 2021 stats.
Looking Forward/Conclusion
On Sunday afternoon, as Dustin Johnson made it clear that he would win the tournament, my dad texted me, “It’s hard to predict humans, eh Sam?”. To be short, yes, it is, but it’s especially hard when you don’t have the right data!
When trying to do the same thing next year, I will incorporate more data that has to do with play leading into the tournament, as this is a crucial aspect that I left out. The analysis will still be based on the idea that certain types of players win at Augusta, so I will still look at player characteristics, but many more stats out there can play a role in determining player success at the Masters.
I’m looking forward to doing this analysis again come April, this time with more data, oh and yeah, I’ll make sure I don’t forget about the most recent nine tournaments next time. Maybe it’s not too hard to predict humans after all, eh, dad?

References:
- Scraper: https://github.com/jdubbert/Scrape-golf-data-from-web
- Data Source: pgatour.com
- SMOTE: https://machinelearningmastery.com/smote-oversampling-for-imbalanced-classification/
My Code:
